The Bulldozer Aftermath: Delving Even Deeper
by Johan De Gelas on May 30, 2012 1:15 AM ESTCaching Analysis
It does not take us long to find a suspect for the lower single-threaded performance of the CMT enabled module: the instruction cache.

The instructions of Cinebench and 7-Zip fit almost perfectly in the instruction cache, but that cannot be said about our MS SQL Server SQL statements. The 8-way 32KB Instruction caches of the latest Intel CPUs are clearly not large enough and shed some light on why the Opteron 6174 performed so well in this benchmark. The older AMD CPU has up to 40% fewer instruction cache misses.
The 2-way 64KB instruction cache was clearly not the optimal choice for caching two threads: the hit rate goes from an excellent 97% down to a mediocre 95% once we enable the second integer thread. It will take some engineering, but increasing the associativity of the L1 instruction cache seems necessary to make sure that the two CMT threads do not hinder each other. Let's move on to the data cache.

Reducing the data cache from 64KB to 16KB was probably necessary in order to keep the die size of the module under control. (A Bulldozer module is less than 80 mm², while two Magny-Cours cores are good for 115 mm².) However this reduction comes with a price: the data cache suffers twice as many misses as before. Intel's 8-way cache does a bit better, but it is not spectacular. Now let's check out the L2 caches.
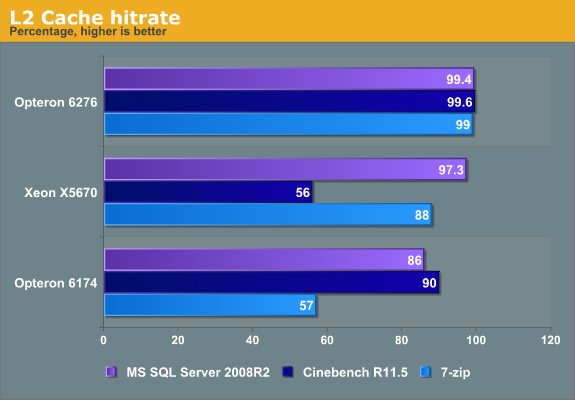
The very low L2 cache hit rates on the older Opteron and Xeon seem like a fluke but that is not the case. In the case of Cinebench, don't forget that this benchmark has an extremely low miss rate in the L1 cache, so most of the easy to cache code and data is already there. The relatively high L2 cache miss rate on the Xeon means that 44% of less than 1% misses the L2 cache--or in other words, almost nothing. The data is almost perfectly cache inside the caches and the data cache hit rate is 99.99%. Most of the L2 cache misses are a few hardly used instructions.
The same is true for the relatively bad hit rate of the Opteron 6174 L2 cache in 7-Zip. The Opteron has a higher L1 data cache hit rate than the other CPUs, so the L2 cache is less accessed. The bad L2 hit rate is not the reason for the lower performance of the older Opteron. Which brings us to the final area of analysis....








84 Comments
View All Comments
Taft12 - Wednesday, May 30, 2012 - link
Johan, this is the best article I've read on Anandtech in quite some time, even better than Jarred, Ryan and Anand have come up with lately.The level of analysis goes far, far beyond just what the benchmarks show.
Bravo!
JohanAnandtech - Thursday, May 31, 2012 - link
Great! Good to read there are still people that like these kinds of analysis!:-)
ct760ster - Wednesday, May 30, 2012 - link
Would be interesting if they could test the aforementioned benchmark in an OS with a customizable kernel like GNU-Linux since code optimization is not possible in most of the proprietary format benchmark.alpha754293 - Wednesday, May 30, 2012 - link
What about the lacklustre FPU performance?The very fact that the FP has to be shared between two integer cores and as far as I know, it cannot run two FP threads at the same time, so for a lot of HPC/computationally heavy workloads - Bulldozer takes a HUGE performance hit. (almost regardless of anything/everything else; although yes, it counts, but remembering that CPUs are glorified calculators, when you take out one of the lanes of the highway and two-lane traffic is now squeezed down to one lane, it's bound to get slower.)
The_Countess - Wednesday, May 30, 2012 - link
except the FP CAN run 2 threads at the same time.only for the as yet pretty much unused 256bit instructions does it need the whole FP unit per clock.
in fact the FP can run 2 threads of 128bit, or 4 even of 64bit.
and a single CPU can use 2x128bit or both can use 1x128.
intel and AMD previously had only 1x128bit capability per core.
so there is no regression in FP performance per core. its just much more flexible.
Zoomer - Wednesday, May 30, 2012 - link
FPU throughput is much more irrelevant nowadays, as many FP intensive HPC computations have already been ported to GPUs. Yes, there may be instances where there might be FP heavy and branchy, not easily parallelization or otherwise unsuitable, but such beasts are few and far between. I can't think of any, to be honest.Iger - Wednesday, May 30, 2012 - link
Thanks a lot, that was a very interesting read!Rael - Wednesday, May 30, 2012 - link
AMD should fire all its marketing department, because these guys accustomed to lie at every announcement they make. The performance gains are multiplied by five or ten, and the per-core advancement, which is close to zero, is presented as 'significant'.I don't believe these announcements anymore.
jabber - Wednesday, May 30, 2012 - link
What the whole of the AMD Marketing team?Thats Tim the caretaker and Trisha on the front desk isnt it?
I thought AMD's marketing budget was around $42.
kyuu - Wednesday, May 30, 2012 - link
Oh hai. You must be new to the human race. Marketing and "stretching the truth" have been synonymous since... forever. AMD is hardly exceptional in this regard. Stop believing anything any marketing department sells you, period.