The Bulldozer Aftermath: Delving Even Deeper
by Johan De Gelas on May 30, 2012 1:15 AM ESTIPC Analysis: What Is Going On?
We decided to focus our attention on our MS SQL Server benchmark and profile it on the most important hardware events (IPC, cache, and branch prediction). We used Intel's VTune Amplifier XE 2011 and AMD's Code Analyst 3.4.1037.88 to get a better understand of this benchmark. To put things into perspective, we compared the results with the extremely popular Cinebench benchmark and the 7-Zip compression benchmark.
Note that VTune has a rather steep learning curve and the numbers presented are more detailed but also harder to interprete than those of Code Analyst. In some cases we had doubts about our measurements on the brand spanking new Xeon E5. That is why we are refraining from publishing those numbers until we are absolutely sure they are accurate, so some of the Xeon E5 numbers are missing.
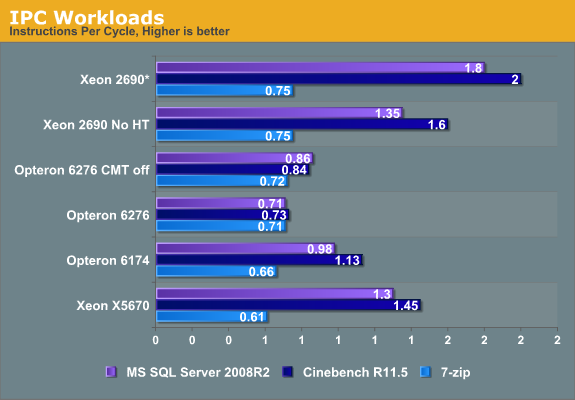
* We add the IPC of the two threads up
It is interesting to note the high Instruction Level Parallelism (ILP) that the Xeon E5 "Sandy Bridge" is able to extract out of these server benchmarks. Almost 1.4 instructions per clock cycle are retired and if you add SMT (Simultaneous Multi Threading), another 0.4 IPC flows through a single core. That is pretty remarkable for a benchmark that consists mostly of SQL statements that result in many branches and loads.
Our Opteron 6200 reveals a bit more about its internal working. Using the extra integer cluster inside the Opteron module causes the separate threads to slow down somewhat. In the case of Cinebench, this is not a real surprise since it contains a lot of SSE floating point commands; a single thread can have the out of order FP cluster all to itself while two threads have to share the SMT capable floating point engine.
But in case of our datamining benchmarks, something else is going on. Single-threaded performance regresses by 18% once you enable the second cluster. We get a 65% speed up (2x 0.71 vs 0.86), which is somewhat lower than the 80% predicted by the AMD slides discussing CMT. So some of the shared resources are slowing down the total performance of our module. We will find out more on the next page.








84 Comments
View All Comments
Taft12 - Wednesday, May 30, 2012 - link
Johan, this is the best article I've read on Anandtech in quite some time, even better than Jarred, Ryan and Anand have come up with lately.The level of analysis goes far, far beyond just what the benchmarks show.
Bravo!
JohanAnandtech - Thursday, May 31, 2012 - link
Great! Good to read there are still people that like these kinds of analysis!:-)
ct760ster - Wednesday, May 30, 2012 - link
Would be interesting if they could test the aforementioned benchmark in an OS with a customizable kernel like GNU-Linux since code optimization is not possible in most of the proprietary format benchmark.alpha754293 - Wednesday, May 30, 2012 - link
What about the lacklustre FPU performance?The very fact that the FP has to be shared between two integer cores and as far as I know, it cannot run two FP threads at the same time, so for a lot of HPC/computationally heavy workloads - Bulldozer takes a HUGE performance hit. (almost regardless of anything/everything else; although yes, it counts, but remembering that CPUs are glorified calculators, when you take out one of the lanes of the highway and two-lane traffic is now squeezed down to one lane, it's bound to get slower.)
The_Countess - Wednesday, May 30, 2012 - link
except the FP CAN run 2 threads at the same time.only for the as yet pretty much unused 256bit instructions does it need the whole FP unit per clock.
in fact the FP can run 2 threads of 128bit, or 4 even of 64bit.
and a single CPU can use 2x128bit or both can use 1x128.
intel and AMD previously had only 1x128bit capability per core.
so there is no regression in FP performance per core. its just much more flexible.
Zoomer - Wednesday, May 30, 2012 - link
FPU throughput is much more irrelevant nowadays, as many FP intensive HPC computations have already been ported to GPUs. Yes, there may be instances where there might be FP heavy and branchy, not easily parallelization or otherwise unsuitable, but such beasts are few and far between. I can't think of any, to be honest.Iger - Wednesday, May 30, 2012 - link
Thanks a lot, that was a very interesting read!Rael - Wednesday, May 30, 2012 - link
AMD should fire all its marketing department, because these guys accustomed to lie at every announcement they make. The performance gains are multiplied by five or ten, and the per-core advancement, which is close to zero, is presented as 'significant'.I don't believe these announcements anymore.
jabber - Wednesday, May 30, 2012 - link
What the whole of the AMD Marketing team?Thats Tim the caretaker and Trisha on the front desk isnt it?
I thought AMD's marketing budget was around $42.
kyuu - Wednesday, May 30, 2012 - link
Oh hai. You must be new to the human race. Marketing and "stretching the truth" have been synonymous since... forever. AMD is hardly exceptional in this regard. Stop believing anything any marketing department sells you, period.