The Bulldozer Aftermath: Delving Even Deeper
by Johan De Gelas on May 30, 2012 1:15 AM ESTCaching Analysis
It does not take us long to find a suspect for the lower single-threaded performance of the CMT enabled module: the instruction cache.

The instructions of Cinebench and 7-Zip fit almost perfectly in the instruction cache, but that cannot be said about our MS SQL Server SQL statements. The 8-way 32KB Instruction caches of the latest Intel CPUs are clearly not large enough and shed some light on why the Opteron 6174 performed so well in this benchmark. The older AMD CPU has up to 40% fewer instruction cache misses.
The 2-way 64KB instruction cache was clearly not the optimal choice for caching two threads: the hit rate goes from an excellent 97% down to a mediocre 95% once we enable the second integer thread. It will take some engineering, but increasing the associativity of the L1 instruction cache seems necessary to make sure that the two CMT threads do not hinder each other. Let's move on to the data cache.

Reducing the data cache from 64KB to 16KB was probably necessary in order to keep the die size of the module under control. (A Bulldozer module is less than 80 mm², while two Magny-Cours cores are good for 115 mm².) However this reduction comes with a price: the data cache suffers twice as many misses as before. Intel's 8-way cache does a bit better, but it is not spectacular. Now let's check out the L2 caches.
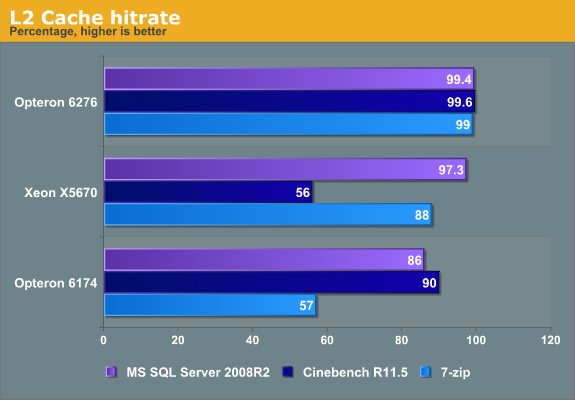
The very low L2 cache hit rates on the older Opteron and Xeon seem like a fluke but that is not the case. In the case of Cinebench, don't forget that this benchmark has an extremely low miss rate in the L1 cache, so most of the easy to cache code and data is already there. The relatively high L2 cache miss rate on the Xeon means that 44% of less than 1% misses the L2 cache--or in other words, almost nothing. The data is almost perfectly cache inside the caches and the data cache hit rate is 99.99%. Most of the L2 cache misses are a few hardly used instructions.
The same is true for the relatively bad hit rate of the Opteron 6174 L2 cache in 7-Zip. The Opteron has a higher L1 data cache hit rate than the other CPUs, so the L2 cache is less accessed. The bad L2 hit rate is not the reason for the lower performance of the older Opteron. Which brings us to the final area of analysis....








84 Comments
View All Comments
Aone - Monday, June 4, 2012 - link
Bulldozer's conception was wrong from the scratch.I told it a few time, let's me explain it here again.
I'm sure everyone of you do remember AMD's own words "one BD module has 80% of throughput of two independent cores".
What does this mean in figures?
Let's take the performance of one core as 1.0 point. Therefore two BD modules would have 3.2 points or in other words less than 10% than 3.0 (performance of three independent cores).
Should I remind that with development of independent cores AMD wouldn't had wasted resources (engineering, transistors, money and time) on design and debugging the shared logic. The chip could have been much smaller due to the fact that the chip would have had only 1MB L2 and 2MB L3 per each core and no shared logic. And all of those released resources could have been allocated for development of a more advanced core.
You see that packing two cores inside a one module was wrong even on the conceptional level. I'm very curious who was the main supporter and decision maker of this approach in AMD.
AMD must through away BD conception and return to standard practice. The only question remains: Does AMD have long enough TTL to do it?
BTW, I recommend to look through Spec results again. The comparison of 12c Opteron 62xx w/ 12c Opteron 61xx is of special interest. And let's not forget that Opteron 62xx submissions have higher freq, faster memory and as well as more advanced compiler version and extended instruction set.
TC2 - Monday, June 18, 2012 - link
I'm agree in 100%!!!The BD uA is "unsuccessful" port from graphics uA. There is many and major drawbacks! Note for example one - to write an optimal software you must adopt an application at algorithmic level (in sense of thread specialization)! This is because the both BD-cores are not the same! Also they shares L1 IC, the number of elements is high, ... and many others uA weaknesses.
evolucion8 - Tuesday, June 17, 2014 - link
Northwood was 20 stage pipelines and Prescott was 31, not 39...tipoo - Wednesday, October 8, 2014 - link
Where is the aftermath?"But what about the fourth show stopper? That is probably one of the most interesting ones because it seems to show up (in a lesser degree) in Sandy Bridge too. However, we're not quite ready with our final investigations into this area, so you'll have to wait a bit longer. To be continued...."