Hot Chips 2020 Live Blog: Marvell ThunderX3 (10:30am PT)
by Dr. Ian Cutress on August 17, 2020 1:30 PM EST- Posted in
- CPUs
- Marvell
- Arm
- Enterprise CPUs
- Live Blog
- ThunderX3
- Hot Chips 32


01:41PM EDT - ThunderX3, now owned by Marvell. They acquired Cavium for TX and TX2
01:41PM EDT - Rabin Sugumar is lead architect for TX3
01:41PM EDT - Sell into the same market as Intel and AMD

01:42PM EDT - Recap of TX2, a 32-core Arm v8.1 design with SMT4
01:42PM EDT - Paved the way for a number of Arm Server CPU firsts
01:42PM EDT - Industry leading perf on bandwidth intensive workloads when launched
01:43PM EDT - Lots of learnings went into TX3
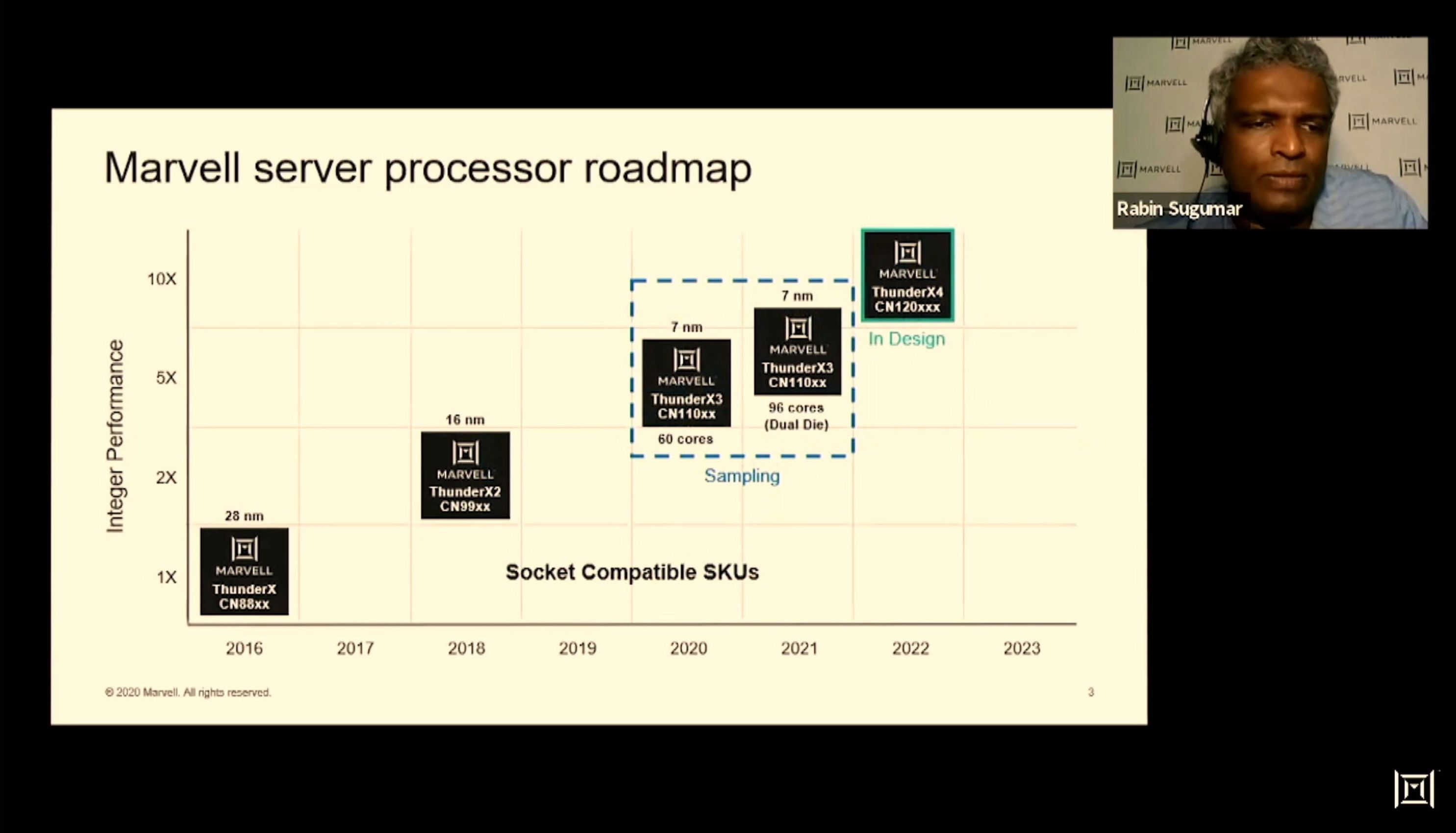
01:43PM EDT - Two versions of TX3 - single die and dual die
01:43PM EDT - ThunderX4 in the works

01:44PM EDT - Up to 60/96 cores, Arm v8.3 with other 8.4 and 8.5 features
01:44PM EDT - 8x DDR4-3200, 64 PCIe 4.0 lanes
01:44PM EDT - On-die monitoring and power management subsystem
01:44PM EDT - Full IO, SATA, USB
01:44PM EDT - 2x-3x perf over TX2 in SPEC
01:44PM EDT - TSMC 7nm
01:44PM EDT - SMT4

01:45PM EDT - Core block diagram
01:45PM EDT - 64KB L1-I, up to 8 instructions/cycle
01:45PM EDT - 8x decode
01:45PM EDT - Most instructions map to a single micro-op
01:46PM EDT - Skid buffer - private to each thread
01:46PM EDT - most other structures are shared
01:46PM EDT - Skid buffer is where the loop buffer is located
01:46PM EDT - 4 ops/cycle dispatch to scheduler
01:47PM EDT - 70 entry scheduler, 220 entry ROB
01:47PM EDT - 7 execution ports, 4 are HP, 3 are Load/Store
01:47PM EDT - 2 are load+store, 1 is store
01:47PM EDT - 512 KB 8-way unified L2

01:47PM EDT - 64 KB I-cache
01:48PM EDT - decoupled fetch (TX2 did not have this)
01:48PM EDT - this allows use the path to walk and fetch cache lines
01:48PM EDT - performance uplift on datacenter codes
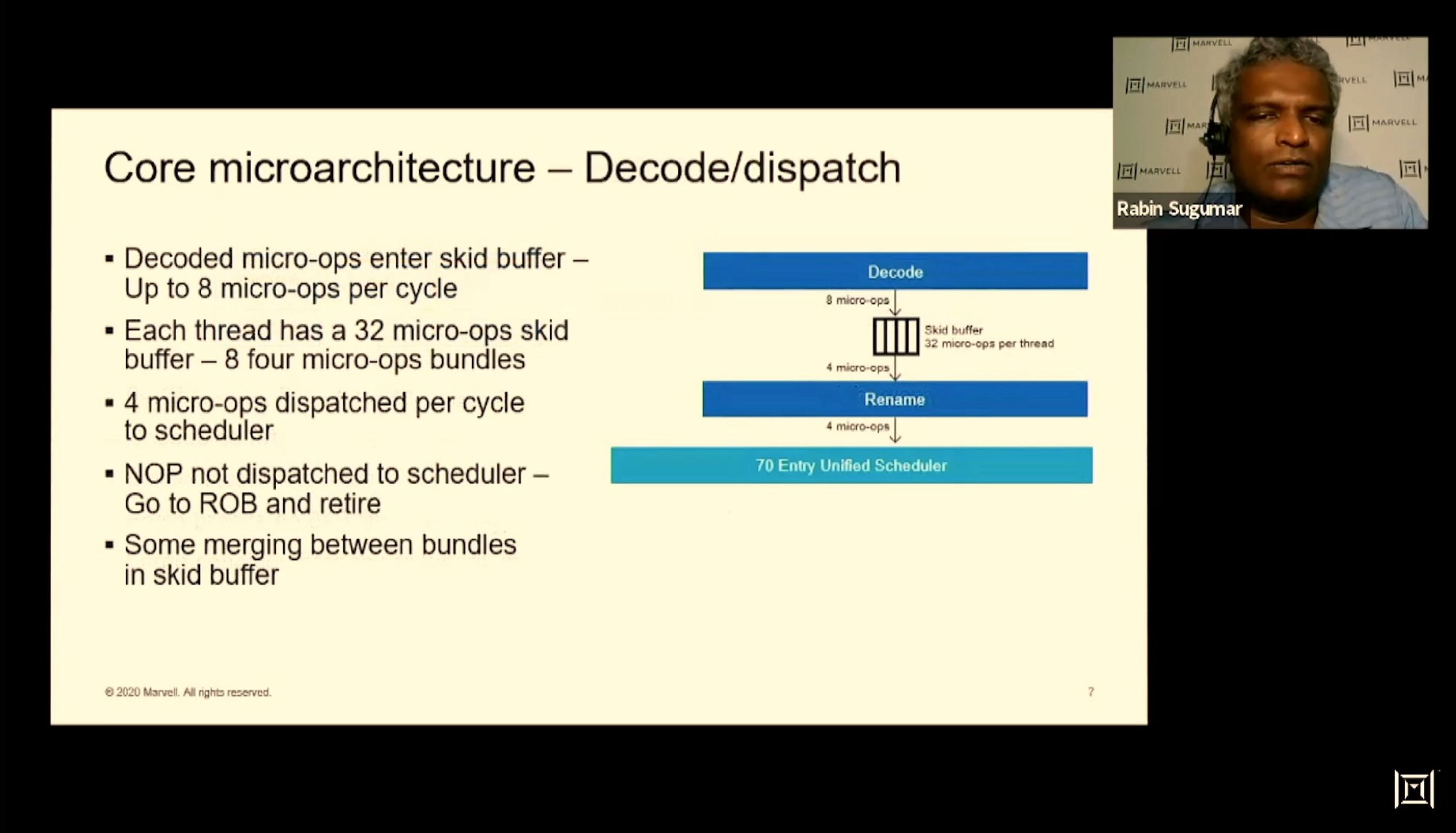
01:49PM EDT - Each thread has a 32-micro-op skid buffer, supports 8x four micro-op bundles
01:49PM EDT - rename tries to bundle microops

01:49PM EDT - Scheduler - 256 entry depths of ports
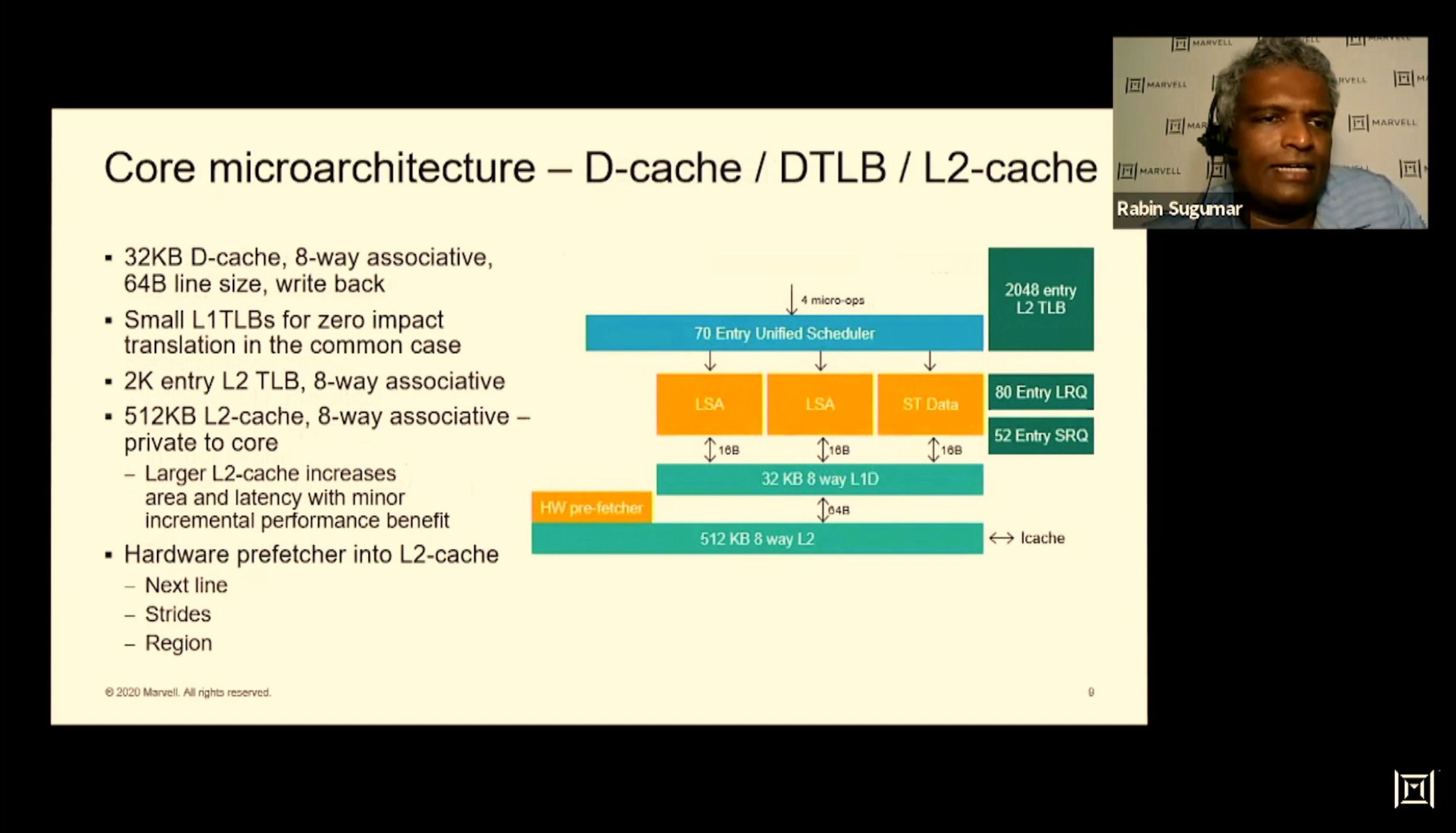
01:50PM EDT - L1 TLB allow 0-cycle
01:50PM EDT - L2 supports strides and regen

01:50PM EDT - Here are all the improvements over TX2 for each change
01:51PM EDT - larger OoO helps 5%, reduce micro-op expansion helps 6%
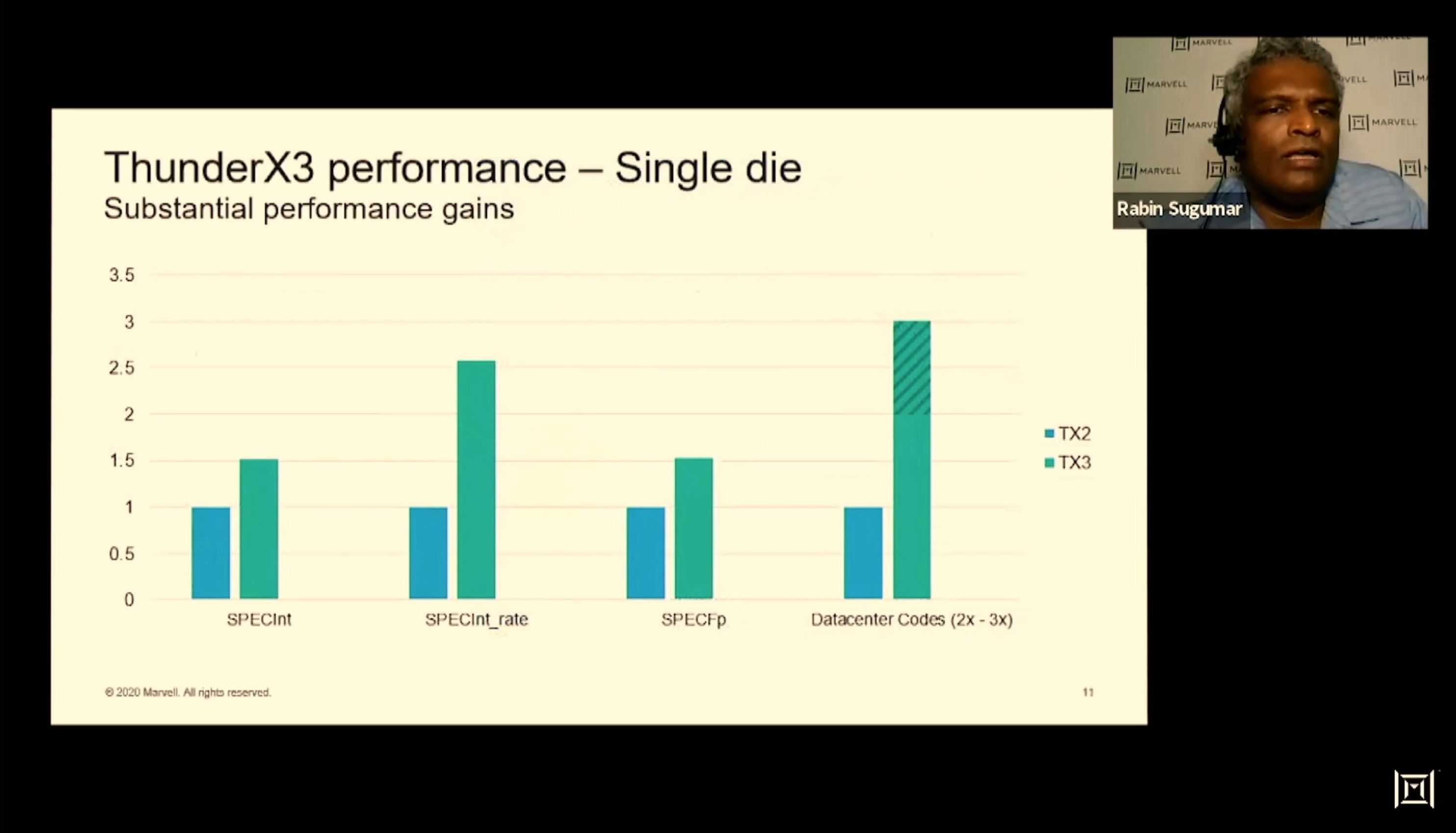
01:51PM EDT - Early perf measurements on TX3 silicon
01:51PM EDT - SPECint 30% from arch, rest is from frequency increase
01:52PM EDT - FP gets slightly better gain than Int
01:52PM EDT - Gains are actually better - these slides are a couple weeks old

01:52PM EDT - As far as OS is concerned, each thread is a full CPU
01:52PM EDT - so four CPUs per core
01:53PM EDT - die area impact of SMT4 is ~5%
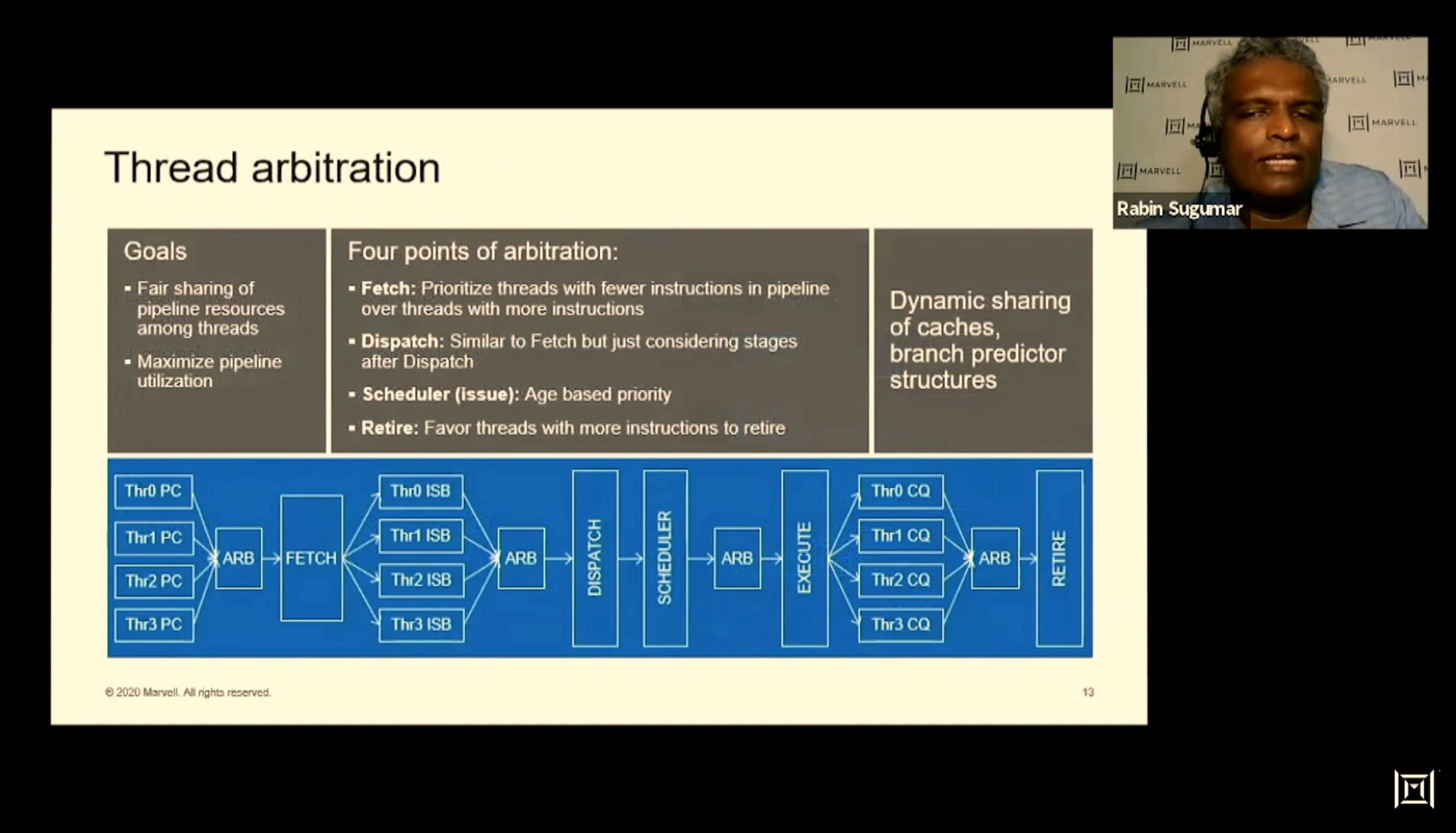
01:53PM EDT - Arbitration to ensure high utilization

01:54PM EDT - Here's the thread speedup
01:55PM EDT - up to 2.21x going to SMT4 for MySQL, 1.28x for x264
01:55PM EDT - (these are SPEC numbers)
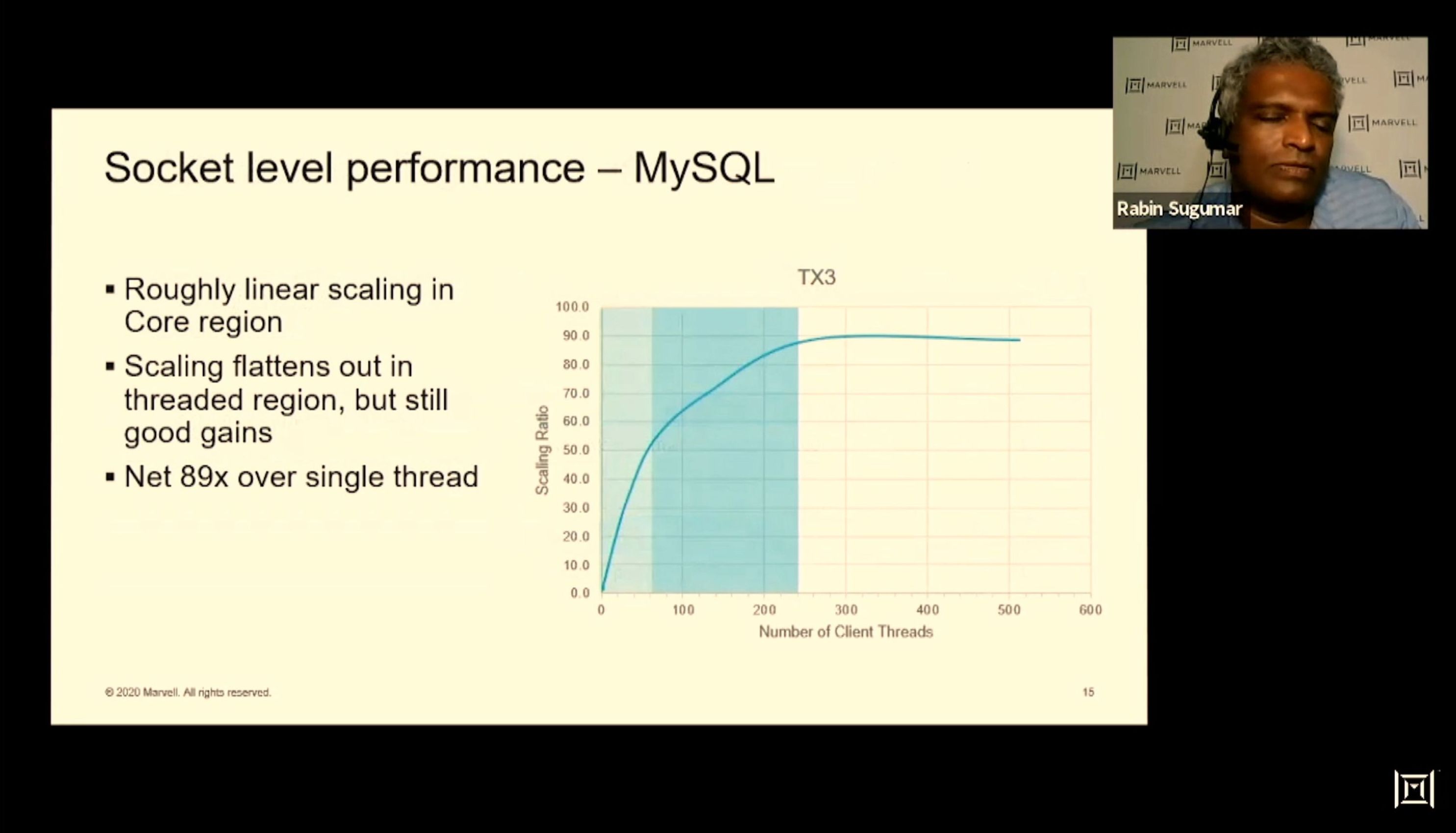
01:55PM EDT - MySQL: 1 thread to 60 cores and 240 threads offers 89x perf improvement
01:56PM EDT - (that's ~1.5x ?)
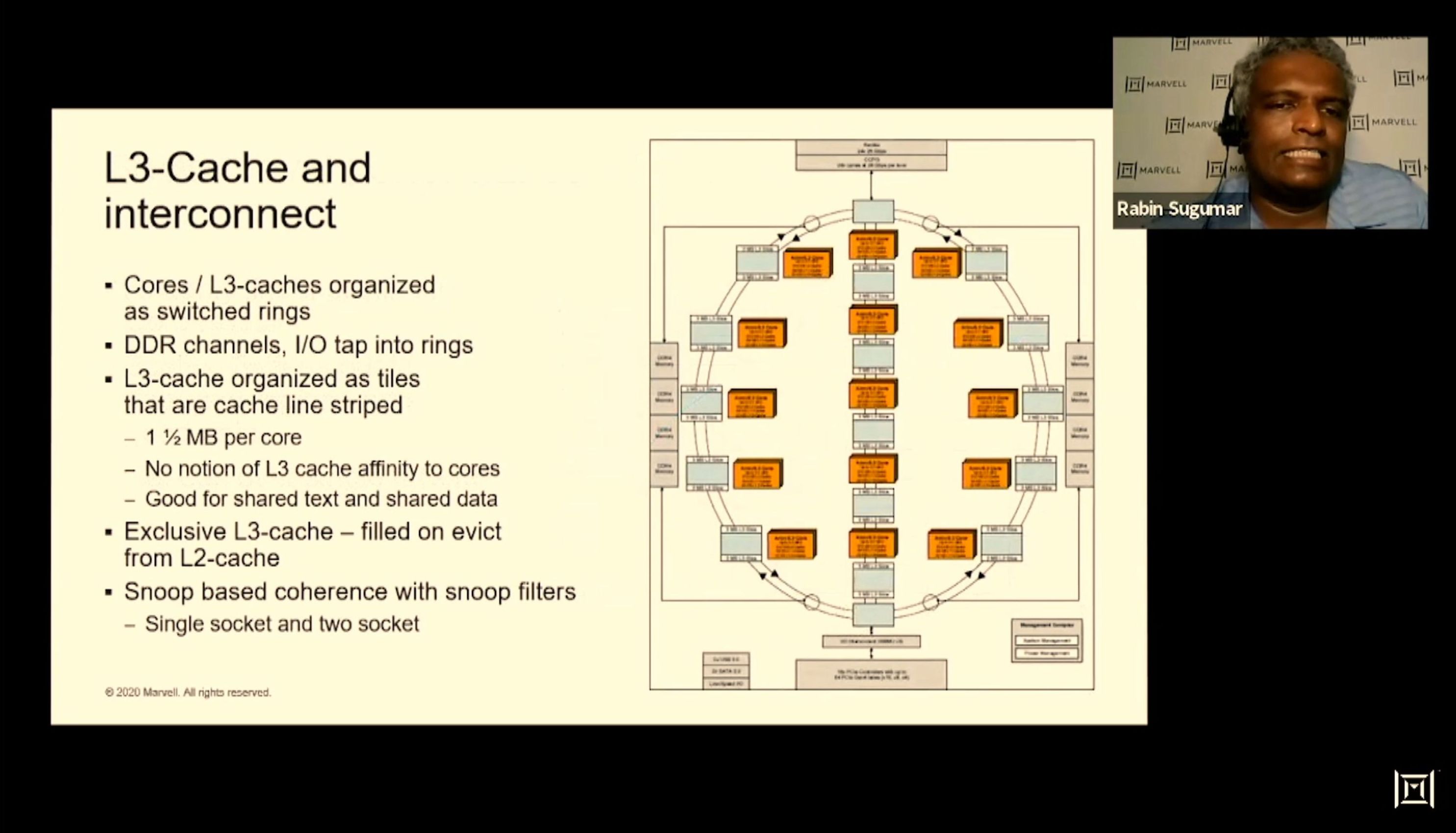
01:56PM EDT - Ring cache with a column
01:56PM EDT - Logically shared but structurally distributed
01:56PM EDT - non-inclusive
01:57PM EDT - Snoop based coherence

01:57PM EDT - Q&A time
01:58PM EDT - Q: Who manufacture? A: TSMC 7nm
01:59PM EDT - Q: No SVE? A: Didn't line up with dev schedule. Better fit for next gen TX. Coming then
02:01PM EDT - Q: Any competitive comparison? What areas does the TX3 chip stand out? A: vs Intel on ST, Intel turbos to higher freq. Even though on a per-GHz TX3 is faster, overall on Intel single thread, Intel tends to be faster. But lower core count on Intel, so our throughput on SPECintrate, we are higher than Intel. On AMD, it's a little bit of a reverse. TX3 does better than AMD on single thread. On throughput, limited cache sharing, AMD does better. But code with more sharing, producers/consumers, then scaling seems to shop. TX3 is better on database performance codes. For Graviton2 - that's a really good chip. Frequency is low, no threading, but its a good chip.
02:02PM EDT - Q: Why did you select switched ring topology vs mesh or single ring? A: tradeoff with area and design changes and performance. On TX2 we had a single ring. Extending that to TX3 didn't work because core count. Mesh would have been a big change, and we would have had to reduce core count. Switched ring seemed a good tradeoff. One of the metrics we use is Stream out of L3 cache - on this on TX3 we see 15%(50%?) more BW per core than TX2 using this topology.
02:03PM EDT - That's a wrap. Next up is z15!








4 Comments
View All Comments
ikjadoon - Monday, August 17, 2020 - link
>Even though on a per-GHz TX3 is faster [than Intel]>TX3 does better than AMD on single thread.
So, better IPC than Intel and higher IPC + ST than AMD (except throughput). I presume these are Cascade-X vs Rome comparisons.
ksec - Tuesday, August 18, 2020 - link
Cloud Vendor would love this as it allow them to Sell 240 vCPU Core Per System. Would love to see how it perform in Real World.name99 - Tuesday, August 18, 2020 - link
"01:56PM EDT - (that's ~1.5x ?)"You can ask different questions.
One question is:
- run a single CPU single threaded and measure your mysql performance, then run the same single CPU 2 or 4-way multithreaded. That was MY assumption for the 1.79/2.21x speedups.
This tells you something about how a single core behaves.
Alternatively you can do what the second graph shows, run 1, 2, 3, ..60 CPUs at a single thread, then start turning on a second thread for each CPU and so on.
This now tells you something about how the uncore behaves, as you start stressing the NoC, the L3, the memory system.
But I share your skepticism. (About SMT in general). Sure, you are getting 1.5x faster performance for MySQL (and there are a class of similar codes that are important), for only (supposedly) 5% higher area. Sounds like a good deal. But is this REALLY a sensible design policy?
(a) That extra 5% also takes a whole lot of extra engineer design and verification time. And opens you up to god knows what possible security issues. And can result in customers complaining about variability in performance so now you start adding extra epicycles to try to make things fairer (Intel has gone through a few iterations of this).
(b) The alternative could have been to just design a lighter version of the core (much the same design, just strip out 30% area that's least helpful to low-IPC throughput-dominant codes like My SQL -- maybe halve the FPU facilities, shrink the L1 and L2 caches, general reduction of the OoO structures?) and offer a version of that design with 90 cores. Same throughput, less engineer effort.
The extent to which this is feasible depends, of course, on the extent to which this design is parameterized and can be easily "recompiled" with different parameters. The result may not be an optimal throughput chip compared to a blank slate design, but good enough.
And there's value to Marvell in having both a big and a small core that they own, for the purposes of all the other chips they produce, beyond just TX3...
The value of SMT is optionality -- you can run the same chip as either a latency engine in SMT1 mode, or a throughput engine in SMT4 mode. But that optionality is of little value to data centers, which have racks dedicated to doing just one job; they're not like personal machines that constantly switch between different types of tasks.
rahvin - Tuesday, August 18, 2020 - link
Based on the previous claims for I and II it won't be better than either AMD or Intel in either single or multithreaded.